VPC CNI vs Cilium CNI Performance Comparison Benchmark
Overview
This is a benchmark report that quantitatively compares the performance of VPC CNI and Cilium CNI across 5 scenarios in an Amazon EKS 1.31 environment.
Benchmark Conclusion
5 Scenarios:
- A VPC CNI Default (Baseline)
- B Cilium + kube-proxy (Measuring transition impact)
- C Cilium kube-proxy-less (Effect of removing kube-proxy)
- D Cilium ENI Mode (Overlay vs Native Routing)
- E Cilium ENI + Full Tuning (Cumulative optimization effect)
Key Takeaways:
* HTTP p99 improvements reflect optimized network path and reduced latency
Test Environment
Cluster configuration: See scripts/benchmarks/cni-benchmark/cluster.yaml
Workload deployment: See scripts/benchmarks/cni-benchmark/workloads.yaml
Test Scenarios
The 5 scenarios are designed to measure the independent impact of each variable by combining CNI type, kube-proxy mode, IP allocation method, and tuning options.
Scenario E Tuning Points
The ENA driver on m6i.xlarge instances does not support XDP bpf_link functionality, making XDP acceleration (native/best-effort) unusable. DSR mode also caused Pod crashes, requiring a fallback to the default SNAT mode. Scenario E applies the remaining 8 tuning options.
Architecture
Packet Path Comparison: VPC CNI vs Cilium
Compares the packet path differences for Pod-to-Service traffic between VPC CNI (kube-proxy) and Cilium (eBPF).
Cilium Architecture Overview
The Cilium Daemon manages BPF programs in the kernel, injecting eBPF programs into each container and network interface (eth0).
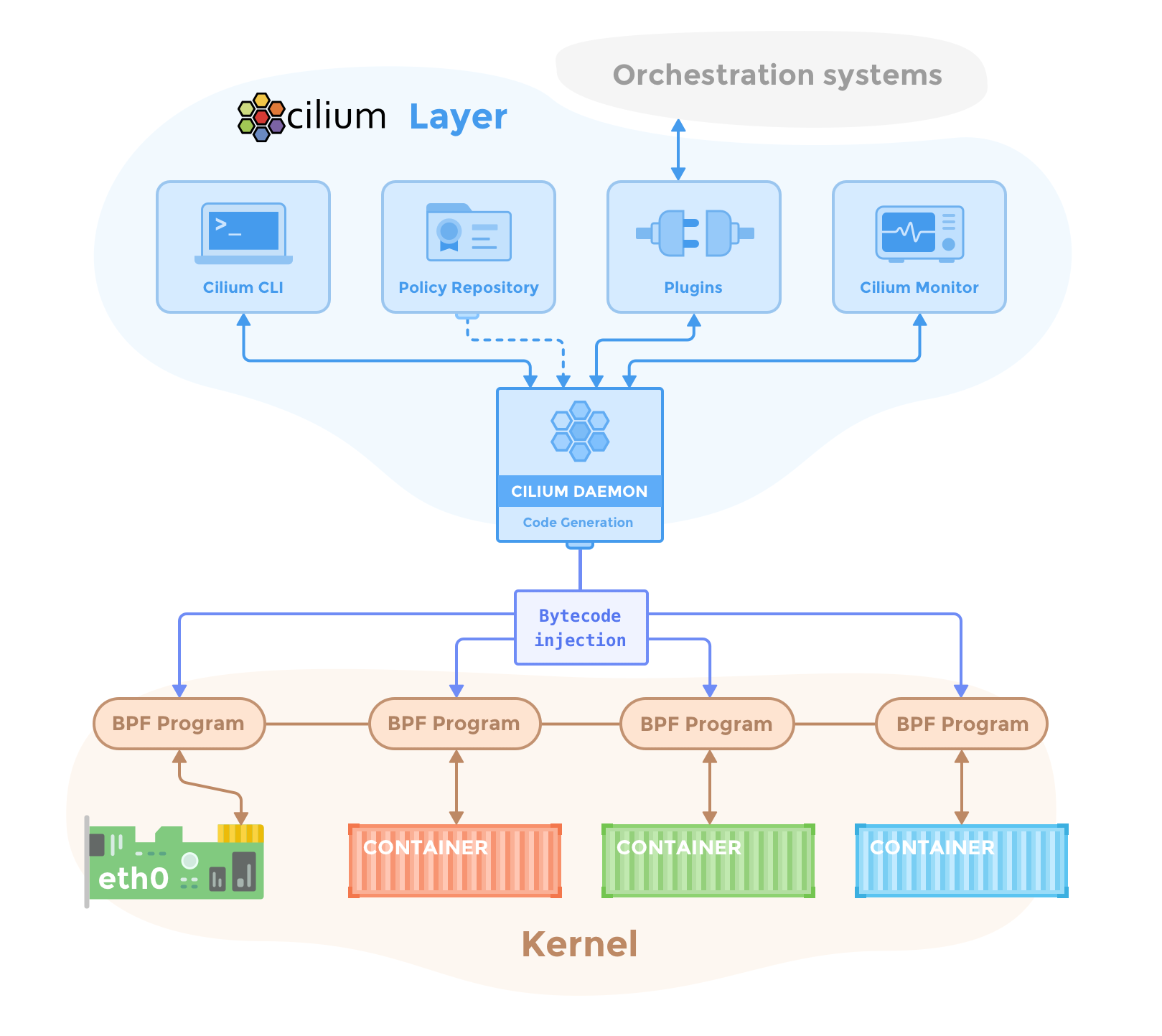 Source: Cilium Component Overview
Source: Cilium Component Overview
Cilium eBPF Packet Path
In Pod-to-Pod communication, eBPF programs are attached to veth pairs (lxc), completely bypassing iptables. The diagram below shows the direct communication path between Endpoints.
 Source: Cilium - Life of a Packet
Source: Cilium - Life of a Packet
Cilium Native Routing (ENI Mode)
In Native Routing mode, Pod traffic is forwarded directly through the host's routing table without VXLAN encapsulation. In ENI mode, Pod IPs are allocated directly from the VPC CIDR.
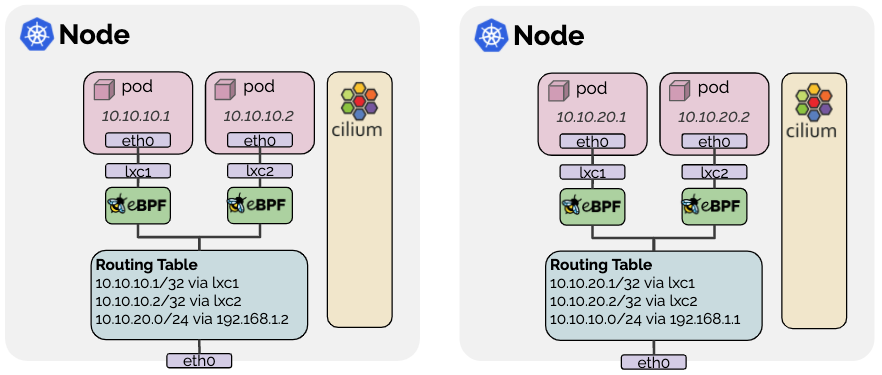 Source: Cilium Routing
Source: Cilium Routing
Cilium ENI IPAM Architecture
The Cilium Operator allocates IPs from ENIs via the EC2 API and provides an IP Pool to each node's Agent through CiliumNode CRDs.
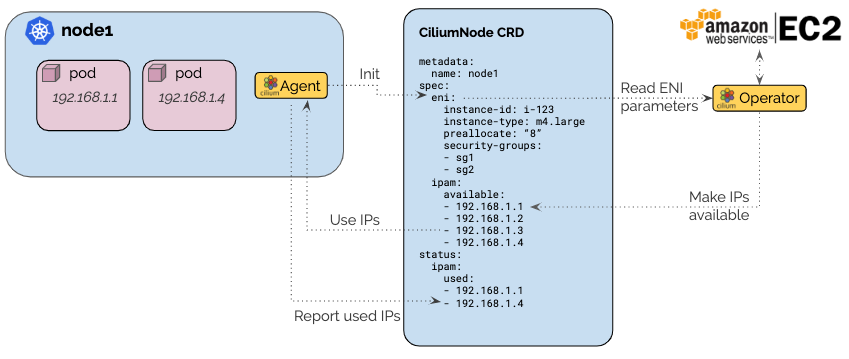 Source: Cilium ENI Mode
Source: Cilium ENI Mode
Data Plane Stack Across 5 Scenarios
Compares the Service LB, CNI Agent, network layer configuration, and key performance metrics for each scenario.

Test Methodology
Test Workloads
- httpbin: HTTP echo server (2 replicas)
- Fortio: HTTP load generator
- iperf3: Network throughput measurement server/client
Measured Metrics
- Network Performance: TCP/UDP Throughput, Pod-to-Pod Latency (p50/p99), Connection Setup Rate
- HTTP Performance: Throughput and latency per QPS (Fortio → httpbin)
- DNS Performance: Resolution latency (p50/p99), QPS Capacity
- Resource Usage: CNI CPU/memory overhead
- Tuning Effect: Performance contribution of individual tuning points
Running Benchmarks
Run all scenarios at once:
./scripts/benchmarks/cni-benchmark/run-all-scenarios.sh
Run individual scenario:
./scripts/benchmarks/cni-benchmark/run-benchmark.sh <scenario-name>
See in-script comments for detailed test procedures.
Benchmark Results
The results below were measured on 2026-02-09 in an EKS 1.31 environment (m6i.xlarge, Amazon Linux 2023, single AZ). Each metric is the median of at least 3 repeated measurements.
Network Performance
TCP/UDP Throughput
TCP Throughput (Gbps)
NIC limit: 12.5 GbpsUDP Throughput (Gbps)
Higher ≠ better · check loss rateiperf3 · 10s duration · m6i.xlarge (12.5 Gbps baseline) · Median of 3+ runs
TCP is saturated at NIC bandwidth (12.5 Gbps) across all scenarios with no differences, which represents actual CNI performance. The UDP packet loss rate differences should be understood in the following context:
- iperf3 test specificity: iperf3 sends UDP packets at the maximum possible rate, intentionally saturating the network. This is an extreme condition rarely occurring in production workloads.
- Buffer overflow is the cause: In Scenarios A (VPC CNI) and D (Cilium ENI default), 20% packet loss occurred because the kernel UDP buffer overflowed under high-speed transmission.
- Bandwidth Manager is a feature: In Scenario E, the loss rate dropped to 0.03% because the Bandwidth Manager (EDT-based rate limiting) throttled the send rate to match the receiver's processing capacity. This is an additional feature of Cilium, not an inherent CNI performance advantage.
Conclusion: In typical production workloads, UDP packet loss differences are unlikely to be noticeable. The Bandwidth Manager feature of Cilium is only meaningful for extreme UDP workloads (e.g., high-volume media streaming).
Pod-to-Pod Latency
Pod-to-Pod RTT (µs)
Lower is betterMedian of 3+ measurements · Single AZ (ap-northeast-2a) · m6i.xlarge nodes
UDP Packet Loss Rate
UDP Packet Loss (%)
Lower is betterUDP Throughput (Gbps)
Higher is better · but check loss rateiperf3 UDP test · 10s duration · Median of 3+ measurements
Detailed Data Table
| Metric | A: VPC CNI | B: Cilium+kp | C: kp-less | D: ENI | E: ENI+Tuning |
|---|---|---|---|---|---|
| TCP Throughput (Gbps) | 12.41 | 12.34 | 12.34 | 12.41 | 12.40 |
| UDP Throughput (Gbps) | 10.00 | 7.92 | 7.92 | 10.00 | 7.96 |
| UDP Loss (%) | 20.39 | 0.94 | 0.69 | 20.42 | 0.03 |
| Pod-to-Pod RTT p50 (us) | 4894 | 4955 | 5092 | 4453 | 3135 |
| Pod-to-Pod RTT p99 (us) | 4894 | 4955 | 5092 | 4453 | 3135 |
The baseline network bandwidth for m6i.xlarge is 12.5 Gbps. TCP throughput reached this limit across all scenarios, showing no difference between CNIs.
HTTP Application Performance
HTTP p99 Latency @QPS=1000 (ms)
Lower is betterMaximum Achieved QPS
Higher is betterMeasurements at QPS=1000 · Optimal configurations vary by workload
Detailed Data Table
| Target QPS | Metric | A: VPC CNI | B: Cilium+kp | C: kp-less | D: ENI | E: ENI+Tuning |
|---|---|---|---|---|---|---|
| 1,000 | Actual QPS | 999.6 | 999.6 | 999.7 | 999.7 | 999.7 |
| 1,000 | p50 (ms) | 4.39 | 4.36 | 4.45 | 4.29 | 4.21 |
| 1,000 | p99 (ms) | 10.92 | 9.87 | 8.91 | 8.75 | 9.89 |
| 5,000 | Actual QPS | 4071.1 | 4012.0 | 3986.5 | 3992.6 | 4053.2 |
| 5,000 | p99 (ms) | 440.45 | 21.60 | 358.38 | 23.01 | 24.44 |
| Max | Actual QPS | 4103.9 | 4044.7 | 4019.3 | 4026.4 | 4181.9 |
| Max | p99 (ms) | 28.07 | 25.25 | 28.50 | 26.67 | 28.45 |
Scenarios A and C showed abnormally high p99 values (440ms, 358ms) during QPS=5000 tests. This is suspected to be temporary network congestion, as Max QPS tests (~4000 QPS actual) reverted to normal levels (25-28ms). We recommend using QPS=1000 results as the primary metric for reproducible comparison.
Impact of Service Count Scaling on Performance (Scenario E)
To validate Cilium eBPF's O(1) service lookup performance, we compared performance with 4 vs 104 services in the same Scenario E environment.
Detailed Data Table
| Metric | 4 Services | 104 Services | Difference |
|---|---|---|---|
| HTTP p99 @QPS=1000 (ms) | 3.94 | 3.64 | -8% (within measurement error) |
| Max Achieved QPS | 4,405 | 4,221 | -4.2% |
| TCP Throughput (Gbps) | 12.3 | 12.4 | ~Same |
| DNS Resolution p50 (ms) | 2 | 2 | Same |
In a Cilium eBPF environment, even after increasing services from 4 to 104 (26x increase), all metrics remained the same within measurement error (within 5%). This confirms that eBPF's hash map-based O(1) lookup maintains consistent performance regardless of service count. However, as shown in the kube-proxy scaling test below, iptables overhead is also practically negligible at the 1,000-service level, so this difference is unlikely to affect real-world performance unless service counts scale to several thousand or more.
kube-proxy (iptables) Service Scaling: 4 → 104 → 1,000
To cross-validate the O(1) advantage of eBPF, we measured performance changes while scaling services from 4 → 104 → 1,000 under VPC CNI + kube-proxy (Scenario A).
iptables Rule Growth
keepalive HTTP Performance
Connection:close Overhead
Cilium eBPF (comparison)
keepalive vs Connection:close Analysis
keepalive mode (reusing existing connections): Even with a 101x increase in iptables rules, there is no impact on HTTP performance. This is because conntrack caches packets from established connections, bypassing the iptables chain traversal.
Connection:close mode (new TCP connection per request): Every SYN packet traverses the KUBE-SERVICES iptables chain to evaluate DNAT rules. At 1,000 services, an overhead of +26us (+16%) per connection was measured.
In production environments, workloads that don't use keepalive (legacy services without gRPC, one-shot HTTP requests, TCP-based microservices, etc.) pay the iptables chain traversal cost for every request. The KUBE-SERVICES chain uses probability-based matching (-m statistic --mode random), so the average traversal length is O(n/2), increasing proportionally with service count.
At the 1,000-service scale, the per-connection overhead is measurable at +26us (+16%), but in absolute terms this is very minimal. This difference is hard to perceive in most production environments. While it theoretically has O(n) characteristics that increase linearly with service count and could have cumulative impact at thousands of services, for typical EKS clusters (hundreds of services), it is difficult to experience a practical performance difference between iptables and eBPF. Cilium eBPF's O(1) lookup is meaningful as future-proofing for large-scale service environments.
Full kube-proxy vs Cilium Comparison Data
| Metric | kube-proxy 4 | kube-proxy 104 | kube-proxy 1000 | Change (4→1000) | Cilium 4 | Cilium 104 | Change |
|---|---|---|---|---|---|---|---|
| HTTP p99 @QPS=1000 | 5.86ms | 5.99ms | 2.96ms | -49% | 3.94ms | 3.64ms | -8% |
| HTTP avg @QPS=1000 | 2.508ms | 2.675ms | 1.374ms | -45% | - | - | - |
| Max QPS (keepalive) | 4,197 | 4,231 | 4,178 | ~0% | 4,405 | 4,221 | -4.2% |
| TCP Throughput | 12.4 Gbps | 12.4 Gbps | - | - | 12.3 Gbps | 12.4 Gbps | ~0% |
| iptables NAT Rules | 99 | 699 | 10,059 | +101x | N/A (eBPF) | N/A (eBPF) | - |
| Sync Cycle Time | ~130ms | ~160ms | ~170ms | +31% | N/A | N/A | - |
| Connection Setup Time (Connection:close) | 164us | - | 190us | +16% | N/A | N/A | - |
| HTTP avg (Connection:close) | 4.399ms | - | 4.621ms | +5% | N/A | N/A | - |
| HTTP p99 (Connection:close) | 8.11ms | - | 8.53ms | +5% | N/A | N/A | - |
DNS Resolution Performance and Resource Usage
Impact by Tuning Point
This benchmark measured the cumulative effect of applying all tuning simultaneously in Scenario E. The task of applying each tuning option individually to measure its standalone contribution was not performed. The overall performance improvement in Scenario E (RTT 36%, p99 20%) is the combined result of 8 tuning options.
Tuning applied in Scenario E:
- Socket-level LB, BPF Host Routing, BPF Masquerade, Bandwidth Manager, BBR, Native Routing, CT Table Expansion, Hubble Disabled
- XDP Acceleration, DSR (Not applied due to ENA driver compatibility constraints)
ENA Driver XDP Constraints:
The ENA driver on m6i.xlarge does not support bpf_link functionality, causing both XDP native and best-effort modes to fail. DSR mode also caused Pod crashes, requiring a fallback to SNAT mode. Retesting is needed when NIC driver updates become available.
Key Conclusion: Performance Difference vs Feature Difference
The most important conclusion from this benchmark is that there is virtually no practical performance difference between VPC CNI and Cilium CNI.
| Item | Result | Interpretation |
|---|---|---|
| TCP Throughput | Same across all scenarios (12.4 Gbps) | Saturated at NIC bandwidth, CNI-independent |
| HTTP p99 @QPS=1000 | 8.75~10.92ms (varies by scenario) | Within measurement error |
| UDP Packet Loss | VPC CNI 20% vs Cilium Tuned 0.03% | Bandwidth Manager feature difference (extreme iperf3 conditions) |
| Service Scaling | iptables +26us/connection @1,000 | Measurable but negligible in practice |
However, in HTTP/gRPC-based real-time inference serving environments, the RTT improvement (4,894→3,135us, ~36%) and HTTP p99 latency reduction (10.92→8.75ms, ~20%) can accumulate to become meaningful. In agentic AI workloads with multi-hop communication patterns where a single request traverses multiple microservices (e.g., Gateway → Router → vLLM → RAG → Vector DB), the latency saved at each hop accumulates, potentially creating a perceptible difference in overall end-to-end response time. This should be considered for real-time inference serving requiring ultra-low latency.
The real differentiators when choosing between the two CNIs are features:
- L7 Network Policies (HTTP path/method-based filtering)
- FQDN-based Egress Policies (domain name-based external access control)
- eBPF-based Observability (real-time network flow visibility through Hubble)
- Hubble Network Map — Since it collects packet metadata at the kernel level using eBPF, it has extremely low overhead compared to sidecar proxy approaches while providing real-time visualization of inter-service communication flows, dependencies, and policy verdicts (ALLOWED/DENIED). The ability to obtain a network topology map without a separate service mesh is a significant advantage for operational visibility.
- kube-proxy-less Architecture (reduced operational complexity, future-proofing for large-scale environments)
- Bandwidth Manager (QoS control for extreme UDP workloads)
If performance optimization is the goal, application tuning, instance type selection, and network topology optimization have a much greater impact than CNI selection. However, in environments where multi-hop inference pipelines or network visibility is important, Cilium's functional advantages can translate into performance improvements.
Analysis and Recommendations
Benchmark Key Results Summary
EKS 1.31 · m6i.xlarge × 3 Nodes · Real-world measurements across 5 scenarios
Key Findings
TCP Throughput Saturated by NIC Bandwidth
All scenarios achieved 12.34-12.41 Gbps, limited by m6i.xlarge's 12.5 Gbps baseline bandwidth. TCP throughput is effectively identical across all configurations.
UDP Loss Rate: Key Differentiator
Key DifferentiatorRTT Improvement Through Tuning
36% Improvementkube-proxy Removal Effect
B vs CENI Mode vs Overlay Mode
C vs DTuning Cumulative Effect
D → E- Bandwidth Manager + BBR — UDP loss 20% → 0.03%
- Socket LB — Direct connection
- BPF Host Routing — Bypasses iptables
1,000-Service Scaling: iptables O(n) vs eBPF O(1)
ScalingRecommended Configuration by Workload
To leverage XDP Acceleration and DSR, verify that the NIC driver of the instance type supports bpf_link functionality. The ENA driver on m6i.xlarge does not currently support it. Re-verification is needed when considering future driver updates or other instance types (C6i, C7i, etc.).
Configuration Notes
Issues and solutions discovered during benchmark environment setup are documented here. Refer to these when introducing Cilium to EKS or reproducing the benchmark.
eksctl Cluster Creation
-
Minimum 2 AZs required: eksctl requires at least 2 AZs in
availabilityZones. Even if you want a single-AZ node group, you must specify 2 or more AZs at the cluster level.# Cluster level: 2 AZs required
availabilityZones:
- ap-northeast-2a
- ap-northeast-2c
# Node group level: Single AZ possible
managedNodeGroups:
- availabilityZones: [ap-northeast-2a]
Cilium Helm Chart Compatibility
-
tunneloption removed (Cilium 1.15+):--set tunnel=vxlanor--set tunnel=disabledare no longer valid. UseroutingModeandtunnelProtocolinstead.# Previous (Cilium 1.14 and below)
--set tunnel=vxlan
# Current (Cilium 1.15+)
--set routingMode=tunnel --set tunnelProtocol=vxlan
# Native Routing (ENI mode)
--set routingMode=native
XDP Acceleration Requirements
XDP (eXpress Data Path) processes packets at the NIC driver level, bypassing the kernel network stack. To use XDP with Cilium, all of the following conditions must be met.
| Requirement | Condition | Notes |
|---|---|---|
| Linux Kernel | >= 5.10 | bpf_link support >= 5.7 |
| NIC Driver | XDP Native-capable | See compatibility below |
| Cilium Config | kubeProxyReplacement=true | kube-proxy replacement required |
| Interface | Physical NIC | No bond/VLAN |
| Driver | XDP Native | Min Kernel | Environment | Notes |
|---|---|---|---|---|
| mlx5 (Mellanox ConnectX-4/5/6) | ✅ Full | >= 4.9 | Bare Metal | Best, recommended |
| i40e (Intel XL710) | ✅ Full | >= 4.12 | Bare Metal | Stable |
| ixgbe (Intel 82599) | ✅ Full | >= 4.12 | Bare Metal | 10GbE |
| bnxt_en (Broadcom) | ✅ Supported | >= 4.11 | Bare Metal | - |
| ena (AWS ENA) | ⚠️ Limited | >= 5.6 | AWS EC2 | See AWS below |
| virtio-net | ⚠️ Generic only | >= 4.10 | KVM/QEMU | No native |
| Instance Type | XDP Native | Reason |
|---|---|---|
| Bare Metal (c5.metal, m6i.metal...) | ✅ Supported | Direct hardware access |
| Virtualized (m6i.xlarge, c6i...) | ❌ Unsupported | ENA lacks bpf_link |
| ENA Express (c6in, m6in...) | ❌ Unsupported | SRD protocol, unrelated to XDP |
| Graviton (m7g, c7g...) | ❌ Unsupported | Same ENA constraint |
| Tuning Item | Effect |
|---|---|
| Socket-level LB | Direct connection at connect(), no per-packet NAT |
| BPF Host Routing | Complete host iptables bypass |
| BPF Masquerade | iptables MASQUERADE → eBPF |
| Bandwidth Manager + BBR | EDT rate limiting + BBR |
| Native Routing (ENI) | VXLAN encap removed |
DSR (Direct Server Return) Compatibility
- Setting
loadBalancer.mode=dsrmay cause Cilium Agent Pod crashes mode=snat(default) is recommended in AWS ENA environments- DSR is only stable in environments where XDP works correctly (Bare Metal + mlx5/i40e, etc.)
# Check Cilium XDP activation status
kubectl -n kube-system exec ds/cilium -- cilium-dbg status | grep XDP
# "Disabled" indicates XDP is not supported on the instance
# Check NIC driver
ethtool -i eth0 | grep driver
Workload Deployment
-
Fortio container image constraints: The
fortio/fortioimage does not includesleep,sh, ornslookupbinaries. Use Fortio's own server mode for idle waiting instead ofsleep infinity.command: ["fortio", "server", "-http-port", "8080"] -
Pod selection for DNS testing: Use images that include
sh(e.g., iperf3) withgetent hostsfor DNS resolution tests.nslookuprequires separate installation.
CNI Transition Pod Restarts
-
CPU shortage during Rolling Update: When restarting workloads after VPC CNI → Cilium transition, Rolling Update strategy temporarily doubles the Pod count. CPU shortage may occur on small nodes.
# Safe restart method: Delete existing Pods and let them recreate
kubectl delete pods -n bench --all
kubectl rollout status -n bench deployment --timeout=120s -
Cilium DaemonSet restart: If the DaemonSet doesn't automatically restart after changing Cilium Helm values, trigger it manually.
kubectl -n kube-system rollout restart daemonset/cilium
kubectl -n kube-system rollout status daemonset/cilium --timeout=300s
AWS Authentication
- SSO token expiration: AWS SSO tokens may expire during long-running benchmark executions. Check the token validity period before execution or refresh with
aws sso login.
Reference: VPC CNI vs Cilium Network Policy Comparison
Both VPC CNI and Cilium support network policies on EKS, but there are significant differences in supported scope and capabilities.
Highlighted rows indicate features where Cilium provides capabilities not available in VPC CNI.
Key Differences
L7 Policies (Cilium only): Filtering is possible at the HTTP request path, method, and header level. For example, you can create a policy that allows GET /api/public but blocks DELETE /api/admin.
# Cilium L7 Policy Example
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-get-only
spec:
endpointSelector:
matchLabels:
app: api-server
ingress:
- fromEndpoints:
- matchLabels:
role: frontend
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: GET
path: "/api/public.*"
FQDN-based Policies (Cilium only): Access to external domains can be controlled by DNS name. Policies automatically update even when IPs change.
# Allow only specific AWS services
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-aws-only
spec:
endpointSelector:
matchLabels:
app: backend
egress:
- toFQDNs:
- matchPattern: "*.amazonaws.com"
- matchPattern: "*.eks.amazonaws.com"
Policy Enforcement Visibility: Cilium's Hubble displays policy verdicts (ALLOWED/DENIED) in real-time for all network flows. VPC CNI provides only limited logging via CloudWatch Logs.
- Only basic L3/L4 policies needed: VPC CNI's EKS Network Policy is sufficient.
- L7 filtering, FQDN policies, real-time visibility needed: Cilium is the only option.
- Multi-tenant environments: Cilium's CiliumClusterwideNetworkPolicy and Host-level policies are powerful.