VPC CNI vs Cilium CNI 성능 비교 벤치마크
개요
Amazon EKS 1.31 환경에서 VPC CNI와 Cilium CNI의 성능을 5개 시나리오로 정량 비교한 벤치마크 보고서입니다.
벤치마크 결론
5개 시나리오:
- A VPC CNI 기본 (베이스라인)
- B Cilium + kube-proxy (전환 영향 측정)
- C Cilium kube-proxy-less (kube-proxy 제거 효과)
- D Cilium ENI 모드 (Overlay vs Native Routing)
- E Cilium ENI + 풀 튜닝 (누적 최적화 효과)
주요 시사점:
* HTTP p99 개선은 최적화된 네트워크 경로와 감소된 지연시간을 반영
테스트 환경
클러스터 구성: scripts/benchmarks/cni-benchmark/cluster.yaml 참조
워크로드 배포: scripts/benchmarks/cni-benchmark/workloads.yaml 참조
테스트 시나리오
5개 시나리오는 CNI, kube-proxy 모드, IP 할당 방식, 튜닝 적용 여부를 조합하여 각 변수의 독립적 영향을 측정하도록 설계했습니다.
시나리오 E 튜닝 포인트
m6i.xlarge 인스턴스의 ENA 드라이버는 XDP bpf_link 기능을 지원하지 않아 XDP acceleration(native/best-effort)을 사용할 수 없습니다. DSR 모드 또한 Pod 크래시를 유발하여 기본 SNAT 모드로 회귀했습니다. 시나리오 E는 나머지 8개 튜닝을 적용한 결과입니다.
아키텍처
패킷 경로 비교: VPC CNI vs Cilium
VPC CNI(kube-proxy)와 Cilium(eBPF)에서 Pod-to-Service 트래픽의 패킷 경로 차이를 비교합니다.
Cilium 아키텍처 개요
Cilium Daemon이 커널의 BPF 프로그램을 관리하며, 각 컨테이너와 네트워크 인터페이스(eth0)에 eBPF 프로그램을 주입합니다.
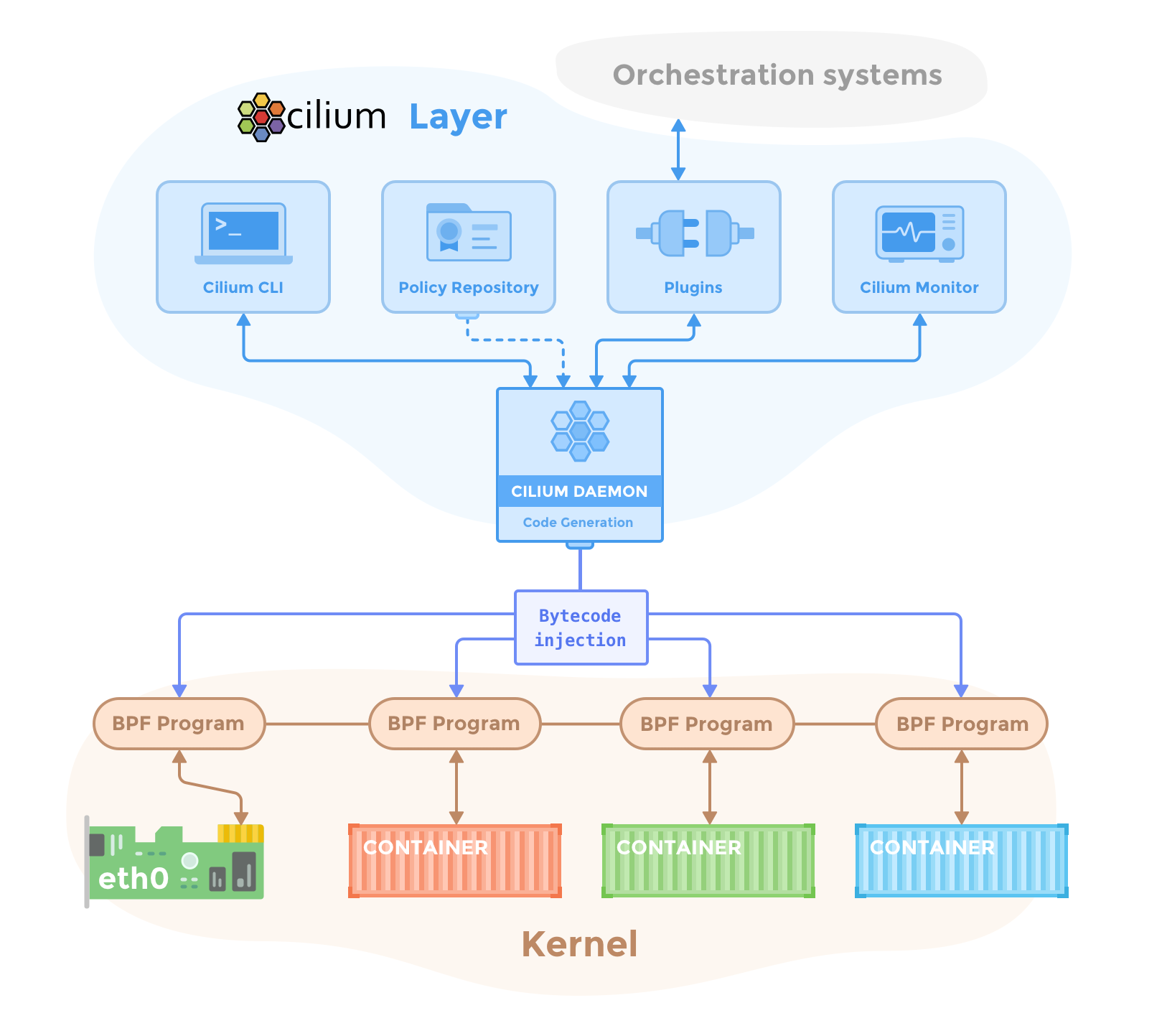 출처:
출처: Cilium eBPF 패킷 경로
Pod-to-Pod 통신에서 eBPF 프로그램은 veth pair(lxc)에 부착되어 iptables를 완전히 우회합니다. 아래 다이어그램은 Endpoint 간 직접 통신 경로를 보여줍�니다.
 출처:
출처: Cilium Native Routing (ENI 모드)
Native Routing 모드에서 Pod 트래픽은 VXLAN 캡슐화 없이 호스트의 라우팅 테이블을 통해 직접 전달됩니다. ENI 모드에서는 Pod IP가 VPC CIDR에서 직접 할당됩니다.
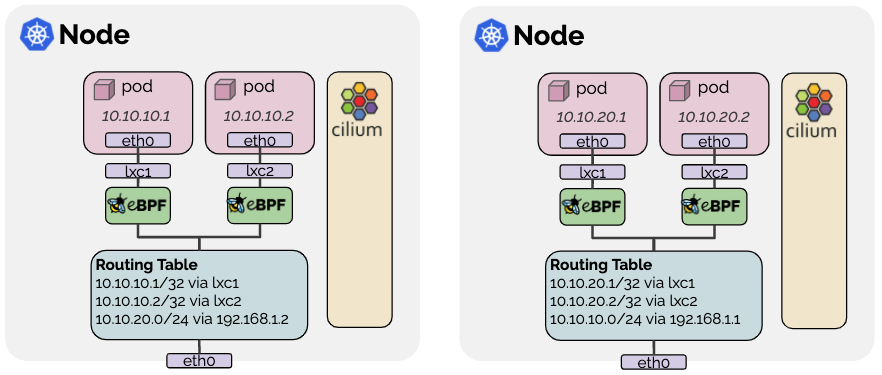 출처: Cilium Routing
출처: Cilium Routing
Cilium ENI IPAM 아키텍처
Cilium Operator가 EC2 API를 통해 ENI에서 IP를 할당하고, CiliumNode CRD를 통해 각 노드의 Agent에 IP Pool을 제공합니다.
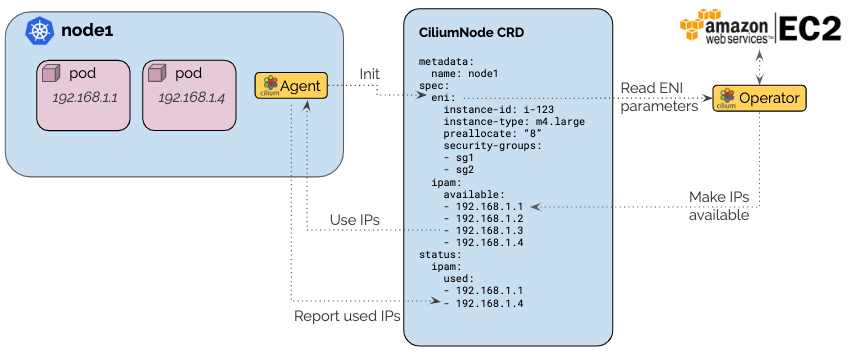 출처: Cilium ENI Mode
출처: Cilium ENI Mode
5개 시나리오별 데이터 플레인 스택
각 시나리오의 Service LB, CNI Agent, 네트워크 계층 구성과 주요 성능 지표를 비교합니다.

테스트 방법
테스트 워크로드
- httpbin: HTTP 에코 서버 (2 replicas)
- Fortio: HTTP 부하 생성기
- iperf3: 네트워크 처리량 측정 서버/클라이언트
측정 메트릭
- 네트워크 성능: TCP/UDP Throughput, Pod-to-Pod Latency (p50/p99), Connection Setup Rate
- HTTP 성능: QPS별 처리량 및 지연 (Fortio → httpbin)
- DNS 성능: 해석 지연 (p50/p99), QPS Capacity
- 리소스 사용량: CNI 자체 CPU/메모리 오버헤드
- 튜닝 효과: 개별 튜닝 포인트의 성능 기여도
벤치마크 실행
전체 시나리오 일괄 실행:
./scripts/benchmarks/cni-benchmark/run-all-scenarios.sh
개별 시나리오 실행:
./scripts/benchmarks/cni-benchmark/run-benchmark.sh <scenario-name>
상세 테스트 절차는 �스크립트 내부 주석 참조.
벤치마크 결과
아래 결과는 2026-02-09 EKS 1.31 환경(m6i.xlarge, Amazon Linux 2023, 단일 AZ)에서 측정되었습니다. 각 메트릭은 최소 3회 반복 측정 후 중앙값을 사용했습니다.
네트워크 성능
TCP/UDP 처리량
TCP Throughput (Gbps)
NIC limit: 12.5 GbpsUDP Throughput (Gbps)
Higher ≠ better · check loss rateiperf3 · 10s duration · m6i.xlarge (12.5 Gbps baseline) · Median of 3+ runs
TCP는 모든 시나리오에서 NIC 대역폭(12.5 Gbps)에 포화되어 차이가 없으며, 이것이 실제 CNI 성능을 대표합니다. UDP에서 관찰된 패킷 손실률 차이는 다음과 같은 맥락에서 이해해야 합니다:
- iperf3 테스트의 특수성: iperf3은 가능한 최대 속도로 UDP 패킷을 전송하여 의도적으로 네트워크를 포화시킵니다. 이는 실제 프로덕션 워크로드에서 거의 발생하지 않는 극단적 조건입니다.
- 버퍼 오버플로우가 원인: 시나리오 A(VPC CNI)와 D(Cilium ENI 기본)에서 20%의 패킷 손실이 발생한 이유는 커널 UDP 버퍼가 고속 전송을 감당하지 못해 오버플로우가 발생했기 때문입니다.
- Bandwidth Manager는 기능: 시나리오 E에서 손실률이 0.03%로 감소한 것은 Bandwidth Manager(EDT 기반 rate limiting)가 전송 속도를 수신 처리 능력에 맞춰 조절했기 때문입니다. 이는 Cilium의 추가 기능이지, CNI 자체의 성능 우위를 의미하지 않습니다.
결론: 일반적인 프로덕션 워크로드에서는 UDP 패킷 손실 차이가 체감되기 어렵습니다. Bandwidth Manager가 필요한 경우(대용량 미디어 스트리밍 등 극한 UDP 워크로드)에 한해 Cilium의 해당 기능이 유의미합니다.
Pod-to-Pod 지연
Pod-to-Pod RTT (µs)
Lower is betterMedian of 3+ measurements · Single AZ (ap-northeast-2a) · m6i.xlarge nodes
UDP 패킷 손실률
UDP Packet Loss (%)
Lower is betterUDP Throughput (Gbps)
Higher is better · but check loss rateiperf3 UDP test · 10s duration · Median of 3+ measurements
상세 데이터 테이블
| 메트릭 | A: VPC CNI | B: Cilium+kp | C: kp-less | D: ENI | E: ENI+튜닝 |
|---|---|---|---|---|---|
| TCP Throughput (Gbps) | 12.41 | 12.34 | 12.34 | 12.41 | 12.40 |
| UDP Throughput (Gbps) | 10.00 | 7.92 | 7.92 | 10.00 | 7.96 |
| UDP Loss (%) | 20.39 | 0.94 | 0.69 | 20.42 | 0.03 |
| Pod-to-Pod RTT p50 (µs) | 4894 | 4955 | 5092 | 4453 | 3135 |
| Pod-to-Pod RTT p99 (µs) | 4894 | 4955 | 5092 | 4453 | 3135 |
m6i.xlarge의 기준 네트워크 대역폭은 12.5 Gbps입니다. 모든 시나리오에서 TCP throughput이 이 한계에 도달하여 CNI별 차이가 나타나지 않았습니다.
HTTP 애플리케이션 성능
HTTP p99 Latency @QPS=1000 (ms)
Lower is betterMaximum Achieved QPS
Higher is betterMeasurements at QPS=1000 · Optimal configurations vary by workload
상세 데이터 테이블
| QPS 목표 | 메트릭 | A: VPC CNI | B: Cilium+kp | C: kp-less | D: ENI | E: ENI+튜닝 |
|---|---|---|---|---|---|---|
| 1,000 | Actual QPS | 999.6 | 999.6 | 999.7 | 999.7 | 999.7 |
| 1,000 | p50 (ms) | 4.39 | 4.36 | 4.45 | 4.29 | 4.21 |
| 1,000 | p99 (ms) | 10.92 | 9.87 | 8.91 | 8.75 | 9.89 |
| 5,000 | Actual QPS | 4071.1 | 4012.0 | 3986.5 | 3992.6 | 4053.2 |
| 5,000 | p99 (ms) | 440.45 | 21.60 | 358.38 | 23.01 | 24.44 |
| Max | Actual QPS | 4103.9 | 4044.7 | 4019.3 | 4026.4 | 4181.9 |
| Max | p99 (ms) | 28.07 | 25.25 | 28.50 | 26.67 | 28.45 |
시나리오 A와 C에서 QPS=5000 테스트 시 p99가 비정상적으로 �높게 측정되었습니다(440ms, 358ms). 이는 일시적인 네트워크 혼잡으로 추정되며, Max QPS 테스트(~4000QPS 실측)에서는 정상 수준(25-28ms)으로 회귀했습니다. 재현성 있는 비교를 위해 QPS=1000 결과를 주요 지표로 사용하는 것을 권장합니다.
서비스 수 확장에 따른 성능 영향 (Scenario E)
Cilium eBPF의 O(1) 서비스 룩업 성능을 검증하기 위해, 동일한 Scenario E 환경에서 서비스 수를 4개 → 104개로 변경한 후 성능을 비교했습니다.
상세 데이터 테이블
| 메트릭 | 4 Services | 104 Services | 차이 |
|---|---|---|---|
| HTTP p99 @QPS=1000 (ms) | 3.94 | 3.64 | -8% (측정 오차 범위) |
| 최대 달성 QPS | 4,405 | 4,221 | -4.2% |
| TCP Throughput (Gbps) | 12.3 | 12.4 | ~동일 |
| DNS Resolution p50 (ms) | 2 | 2 | 동일 |
Cilium eBPF 환경에서 서비스 수를 4개에서 104개로 26배 증가시켰음에도 모든 메트릭이 측정 오차 범위(5% 이내)에서 동일했습니다. 이는 eBPF의 해시 맵 기반 O(1) 룩업이 서비스 수에 무관하게 일정한 성능을 유지함을 확인합니다. 다만, 아래 kube-proxy 스케일링 테스트에서 보듯 iptables 방식의 오버헤드도 1,000개 서비스 수준에서는 실질적으로 미미하여, 서비스 수가 수천 개 이상으로 대규모화되지 않는 한 이 차이가 실제 성능에 영향을 미칠 가능성은 낮습니다.
kube-proxy (iptables) 서비스 스케일링: 4 → 104 → 1,000개
eBPF의 O(1) 장점을 대조 검증하기 위해 VPC CNI + kube-proxy (시나리오 A)에서 서비스 수를 4개 → 104개 → 1,000개로 확장하며 성능 변화를 측정했습니다.
iptables 규칙 증가
keepalive HTTP 성능
Connection:close 오버헤드
Cilium eBPF (비교)
keepalive vs Connection:close 비교 분석
keepalive 모드 (기존 연결 재사용): iptables 규칙이 101배 증가해도 HTTP 성능에 영향 없음. 이는 conntrack이 이미 설정된 연결의 패킷을 캐시하여 iptables 체인 순회를 우회하기 때문입니다.
Connection:close 모드 (매 요청마다 신규 TCP 연결): 모든 SYN 패킷에서 KUBE-SERVICES iptables 체인을 순회하여 DNAT 규칙을 평가합니다. 1,000개 서비스에서 연결당 +26µs (+16%) 오버헤드가 측정되었습니다.
프로덕션 환경에서 keepalive를 사용하지 않는 워�크로드(gRPC 미사용 레거시 서비스, 단발성 HTTP 요청, TCP 기반 마이크로서비스 등)는 매 요청마다 iptables 체인 순회 비용을 지불합니다. KUBE-SERVICES 체인은 확률 기반 매칭(-m statistic --mode random)을 사용하므로 평균 순회 길이는 O(n/2)이며, 서비스 수에 비례하여 증가합니다.
1,000개 서비스 규모에서 연결당 오버헤드는 +26µs(+16%)로 측정 가능하지만, 절대값으로는 매우 미미한 수준입니다. 이는 대부분의 프로덕션 환경에서 체감하기 어려운 차이입니다. 이론적으로 서비스 수에 선형 증가하는 O(n) 특성을 가지므로 수천 개 이상의 서비스에서는 누적 영향이 있을 수 있으나, 일반적인 EKS 클러스터(수백 개 서비스)에서는 iptables와 eBPF 간 실질적 성능 차이를 경험하기 어렵습니다. Cilium eBPF의 O(1) 조회는 대규모 서비스 환경에 대한 미래 대비(future-proofing) 측면에서 의미가 있습니다.
kube-proxy vs Cilium 전체 비교 데이터
| 메트릭 | kube-proxy 4개 | kube-proxy 104개 | kube-proxy 1000개 | 변화 (4→1000) | Cilium 4개 | Cilium 104개 | 변화 |
|---|---|---|---|---|---|---|---|
| HTTP p99 @QPS=1000 | 5.86ms | 5.99ms | 2.96ms | -49% | 3.94ms | 3.64ms | -8% |
| HTTP avg @QPS=1000 | 2.508ms | 2.675ms | 1.374ms | -45% | - | - | - |
| 최대 QPS (keepalive) | 4,197 | 4,231 | 4,178 | ~0% | 4,405 | 4,221 | -4.2% |
| TCP 처리량 | 12.4 Gbps | 12.4 Gbps | - | - | 12.3 Gbps | 12.4 Gbps | ~0% |
| iptables NAT 규칙 수 | 99 | 699 | 10,059 | +101배 | N/A (eBPF) | N/A (eBPF) | - |
| Sync 주기 시간 | ~130ms | ~160ms | ~170ms | +31% | N/A | N/A | - |
| 연결당 설정 시간 (Connection:close) | 164µs | - | 190µs | +16% | N/A | N/A | - |
| HTTP avg (Connection:close) | 4.399ms | - | 4.621ms | +5% | N/A | N/A | - |
| HTTP p99 (Connection:close) | 8.11ms | - | 8.53ms | +5% | N/A | N/A | - |
DNS 해석 성능 및 리소스 사용량
튜닝 포인트별 영향도
본 벤치마크는 시나리오 E에서 모든 튜닝을 동시 적용한 누적 효과를 측정했습니다. 각 튜닝 옵션을 개별 적용하여 단독 기여도를 측정하는 작업은 수행하지 않았습니다. 시나리오 E의 전체 성능 개선(RTT 36%, p99 20%)은 8개 튜닝의 복합 결과입니다.
시나리오 E에서 적용된 튜닝:
- ✅ Socket-level LB, BPF Host Routing, BPF Masquerade, Bandwidth Manager, BBR, Native Routing, CT Table 확장, Hubble 비활성화
- ❌ XDP Acceleration, DSR (ENA 드라이버 호환성 제약으로 미적용)
ENA 드라이버 XDP 제약사항:
m6i.xlarge의 ENA 드라이버는 bpf_link 기능을 지원하지 않아 XDP native 및 best-effort 모드 모두 실패합니다. DSR 모드 또한 Pod 크래시를 유발하여 SNAT 모드로 회귀했습니다. 향후 NIC 드라이버 업데이트 시 재시도가 필요합니다.
핵심 결론: 성능 차이 vs 기능 차이
이번 벤치마크의 가장 중요한 결론은 VPC CNI와 Cilium CNI 간에 실질적인 성능 차이는 거의 없다는 점입니다.
| 항목 | 결과 | 해석 |
|---|---|---|
| TCP Throughput | 모든 시나리오 동일 (12.4 Gbps) | NIC 대역폭에 포화, CNI 무관 |
| HTTP p99 @QPS=1000 | 8.75~10.92ms (시나리오별 변동) | 측정 오차 범위 내 |
| UDP 패킷 손실 | VPC CNI 20% vs Cilium 튜닝 0.03% | Bandwidth Manager 기능 유무 차이 (iperf3 극한 조건) |
| 서비스 스케일링 | iptables +26µs/연결 @1,000개 | 측정 가능하나 실환경에서 미미 |
다만, HTTP/gRPC 기반 실시간 추론 서빙 환경에서는 RTT 개선(4,894→3,135µs, 약 36%)과 HTTP p99 지연 감소(10.92→8.75ms, 약 20%)가 누적되어 유의미할 수 있습니다. Agentic AI 워크로드처럼 하나의 요청이 여러 마이크로서비스를 거치는 multi-hop 통신 패턴(예: Gateway → Router → vLLM → RAG → Vector DB)에서는 hop마다 절감된 지연이 누적되므로, 전체 end-to-end 응답 시간에서 체감 가능한 차이가 발생할 수 있습니다. 초저지연이 요구되는 실시간 추론 서빙에서는 이 점을 고려할 필요가 있습니다.
두 CNI를 선택할 때 고려해야 할 진짜 차이점은 기능입니다:
- L7 네트워크 정책 (HTTP 경로/메서드 기반 필터링)
- FQDN 기반 Egress 정책 (도메인 이름으로 외부 접근 제어)
- eBPF 기반 관찰성 (Hubble을 통한 실시간 네트워크 흐름 가시성)
- Hubble 네트워크 맵 — eBPF 기반으로 커널 수준에서 패킷 메타데이터를 수집하므로 사이드카 프록시 방식 대비 오버헤드가 극히 낮으면서도 서비스 간 통신 흐름, 의존성, 정책 판정(ALLOWED/DENIED)을 실시간 시각화할 수 있습니다. 별도의 서비스 메시 없이도 네트워크 토폴로지 맵을 확보할 수 있다는 점은 운영 가시성 측면에서 큰 장점입니다.
- kube-proxy-less 아키텍처 (운영 복잡도 감소, 대규모 환경 미래 대비)
- Bandwidth Manager (극한 UDP 워크로드의 QoS 제어)
성능 최적화가 목적이라면 CNI 선택보다 애플리케이션 튜닝, 인스턴스 타입 선정, 네트워크 토폴로지 최적화가 훨씬 큰 영향을 미칩니다. 다만 multi-hop 추론 파이프라인이나 네트워크 가시성이 중요한 환경에서는 Cilium의 기능적 이점이 성능 개선으로 이어질 수 있습니다.
분석 및 권장사항
벤치마크 핵심 결과 요약
EKS 1.31 · m6i.xlarge × 3 Nodes · 5개 시나리오 실측 데이터 기반
주요 발견사항
TCP Throughput은 NIC 대역폭에 포화
모든 시나리오에서 12.34-12.41 Gbps를 달성했으며, m6i.xlarge의 12.5 Gbps baseline 대역폭에 의해 제한됩니다. TCP throughput은 모든 구성에서 사실상 동일합니다.
UDP Loss Rate: 핵심 차별화 요소
핵심 차별화 요소튜닝을 통한 RTT 개선
36% 개선kube-proxy 제거의 효과
B vs C 비교ENI 모드 vs Overlay 모드
C vs D튜닝 적용의 누적 효과
D → E 전환- Bandwidth Manager + BBR — UDP loss 20% → 0.03%
- Socket LB — 직접 연결
- BPF Host Routing — iptables 우회
1,000개 서비스 스케일링: iptables O(n) vs eBPF O(1)
스케일링워크로드별 권장 구성
XDP Acceleration과 DSR을 활용하려면 인스턴스 타입의 NIC 드라이버가 bpf_link 기능을 지원하는지 확인하세요. m6i.xlarge의 ENA 드라이버는 현재 미지원입니다. 향후 드라이버 업데이트 또는 다른 인스턴스 타입(C6i, C7i 등) 고려 시 재검증이 필요합니다.
구성 시 주의사항
벤치마크 환경 구성 과정에서 발견된 이슈와 해결 방법을 정리합니다. Cilium을 EKS에 도입하거나 벤치마크를 재현할 때 참고하세요.
eksctl 클러스터 생성
-
최소 2개 AZ 필요: eksctl은
availabilityZones에 최소 2개 AZ를 요구합니다. 단일 AZ 노드그룹��을 원해도 클러스터 수준에서는 2개 이상의 AZ를 지정해야 합니다.# 클러스터 수준: 2개 AZ 필수
availabilityZones:
- ap-northeast-2a
- ap-northeast-2c
# 노드그룹 수준: 단일 AZ 가능
managedNodeGroups:
- availabilityZones: [ap-northeast-2a]
Cilium Helm 차트 호환성
-
tunnel옵션 제거됨 (Cilium 1.15+):--set tunnel=vxlan또는--set tunnel=disabled는 더 이상 유효하지 않습니다. 대신routingMode와tunnelProtocol을 사용하세요.# 이전 (Cilium 1.14 이하)
--set tunnel=vxlan
# 현재 (Cilium 1.15+)
--set routingMode=tunnel --set tunnelProtocol=vxlan
# Native Routing (ENI 모드)
--set routingMode=native
XDP 가속 사용 조건
XDP(eXpress Data Path)는 NIC 드라이버 수준에서 패킷을 처리하여 커널 네트워크 스택을 우회합니다. Cilium에서 XDP를 사용하려면 다음 조건을 모두 충족해야 합니다.
| 요구사항 | 조건 | 비고 |
|---|---|---|
| Linux 커널 | >= 5.10 | bpf_link 지원 >= 5.7 |
| NIC 드라이버 | XDP Native 지원 | See compatibility below |
| Cilium 설정 | kubeProxyReplacement=true | kube-proxy 대체 필수 |
| 인터페이스 | 물리 NIC | bond/VLAN 미지원 |
| 드라이버 | XDP Native | 최소 커널 | 환경 | 비고 |
|---|---|---|---|---|
| mlx5 (Mellanox ConnectX-4/5/6) | ✅ 완전 지원 | >= 4.9 | Bare Metal | 최적, 권장 |
| i40e (Intel XL710) | ✅ 완전 지원 | >= 4.12 | Bare Metal | 안정적 |
| ixgbe (Intel 82599) | ✅ 완전 지원 | >= 4.12 | Bare Metal | 10GbE |
| bnxt_en (Broadcom) | ✅ 지원 | >= 4.11 | Bare Metal | - |
| ena (AWS ENA) | ⚠️ 제한적 | >= 5.6 | AWS EC2 | 아래 AWS 참조 |
| virtio-net | ⚠️ Generic만 | >= 4.10 | KVM/QEMU | Native 미지원 |
| 인스턴스 유형 | XDP Native | 이유 |
|---|---|---|
| Bare Metal (c5.metal, m6i.metal...) | ✅ 지원 | 하드웨어 직접 접근 |
| Virtualized (m6i.xlarge, c6i...) | ❌ Unsupported | bpf_link 미구현 |
| ENA Express (c6in, m6in...) | ❌ Unsupported | SRD 프로토콜, XDP와 무관 |
| Graviton (m7g, c7g...) | ❌ Unsupported | 동일 ENA 제약 |
| 튜닝 항목 | 효과 |
|---|---|
| Socket-level LB | connect() 시점 직접 연결, per-packet NAT 없음 |
| BPF Host Routing | 호스트 iptables 완전 우회 |
| BPF Masquerade | iptables MASQUERADE → eBPF |
| Bandwidth Manager + BBR | EDT 기반 rate limiting + BBR |
| Native Routing (ENI) | VXLAN 캡슐화 제거 |
DSR (Direct Server Return) 호환성
loadBalancer.mode=dsr설정 시 Cilium Agent Pod 크래시 발생 가능- AWS ENA 환경에서는
mode=snat(기본값) 권장 - DSR은 XDP가 정상 동작하는 환경(Bare Metal + mlx5/i40e 등)에서만 안정적
# Cilium XDP 활성화 상태 확인
kubectl -n kube-system exec ds/cilium -- cilium-dbg status | grep XDP
# "Disabled" 표시 시 해당 인스턴스에서 XDP 미지원
# NIC 드라이버 확인
ethtool -i eth0 | grep driver
워크로드 배포
-
Fortio 컨테이너 이미지 제약:
fortio/fortio이미지에는sleep,sh,nslookup바이너리가 없습니다. Idle 대기 시sleep infinity대신 Fortio 자체 서버 모드를 사용하세요.command: ["fortio", "server", "-http-port", "8080"] -
DNS 테스트용 Pod 선택: DNS 해석 테스트는
sh가 포함된 이미지(예: iperf3)에서getent hosts를 사용하세요.nslookup은 별도 설치가 필요합니다.
CNI 전환 시 Pod 재시작
-
Rolling Update 시 CPU 부족: VPC CNI → Cilium 전환 후 워크로드를 재시작할 때, Rolling Update 전략은 Pod 수를 일시적으로 2배로 늘립니다. 소규모 노드에서 CPU 부족이 발생할 수 있습니다.
# 안전한 재시작 방법: 기존 Pod 삭제 후 재생성
kubectl delete pods -n bench --all
kubectl rollout status -n bench deployment --timeout=120s -
Cilium DaemonSet 재시작: Cilium Helm 값 변경 후 DaemonSet이 자동 재시작되지 않으면 수동으로 트리거하세요.
kubectl -n kube-system rollout restart daemonset/cilium
kubectl -n kube-system rollout status daemonset/cilium --timeout=300s
AWS 인증
- SSO 토큰 만료: 장시간 벤치마크 실행 중 AWS SSO 토큰이 만료될 수 있습니다. 실행 전 토큰 유효 시간을 확인하거나,
aws sso login으로 갱신하세요.
참고: VPC CNI vs Cilium 네트워크 정책 비교
EKS에서 VPC CNI와 Cilium 모두 네트워크 정책을 지원하지만, 지원 범위와 기능에 큰 차이가 있습니다.
Highlighted rows indicate features where Cilium provides capabilities not available in VPC CNI.
주요 차이점
L7 정책 (Cilium 전용): HTTP 요청의 경로, 메서드, 헤더 수준에서 필터링이 가능합니다. 예를 들어 GET /api/public은 허용하고 DELETE /api/admin은 차단하는 정책을 설정할 수 있습니다.
# Cilium L7 정책 예시
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-get-only
spec:
endpointSelector:
matchLabels:
app: api-server
ingress:
- fromEndpoints:
- matchLabels:
role: frontend
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: GET
path: "/api/public.*"
FQDN 기반 정책 (Cilium 전용): 외부 도메인에 대한 접근을 DNS 이름으로 제어할 수 있습니다. IP가 변경되어도 정책이 자동으로 업데이트됩니다.
# 특정 AWS 서비스만 허용
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-aws-only
spec:
endpointSelector:
matchLabels:
app: backend
egress:
- toFQDNs:
- matchPattern: "*.amazonaws.com"
- matchPattern: "*.eks.amazonaws.com"
정책 시행 가시성: Cilium의 Hubble은 모든 네트워크 흐름에 대해 정책 판정(ALLOWED/DENIED)을 실시간으로 표시합니다. VPC CNI는 CloudWatch Logs를 통해 제한적인 로깅만 제공합니다.
- 기본 L3/L4 정책만 필요: VPC CNI의 EKS Network Policy로 충분합니다.
- L7 필터링, FQDN 정책, 실시간 가시성 필요: Cilium이 유일한 선택지입니다.
- 멀티테넌트 환경: Cilium의 CiliumClusterwideNetworkPolicy와 Host-level 정책이 강력합니다.